MLOps: DevOps for Machine Learning
Table of Contents
Also published in towards data science
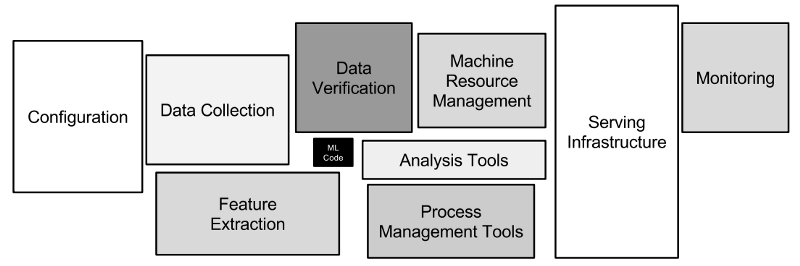
One of the known truths of the Machine Learning(ML) world is that it takes a lot longer to deploy ML models to production than to develop it. According to the famous paper “Hidden Technical Debt in Machine Learning Systems”:
“Only a small fraction of real-world ML systems is composed of the ML code, as shown by the small black box in the middle(see diagram below). The required surrounding infrastructure is vast and complex.”
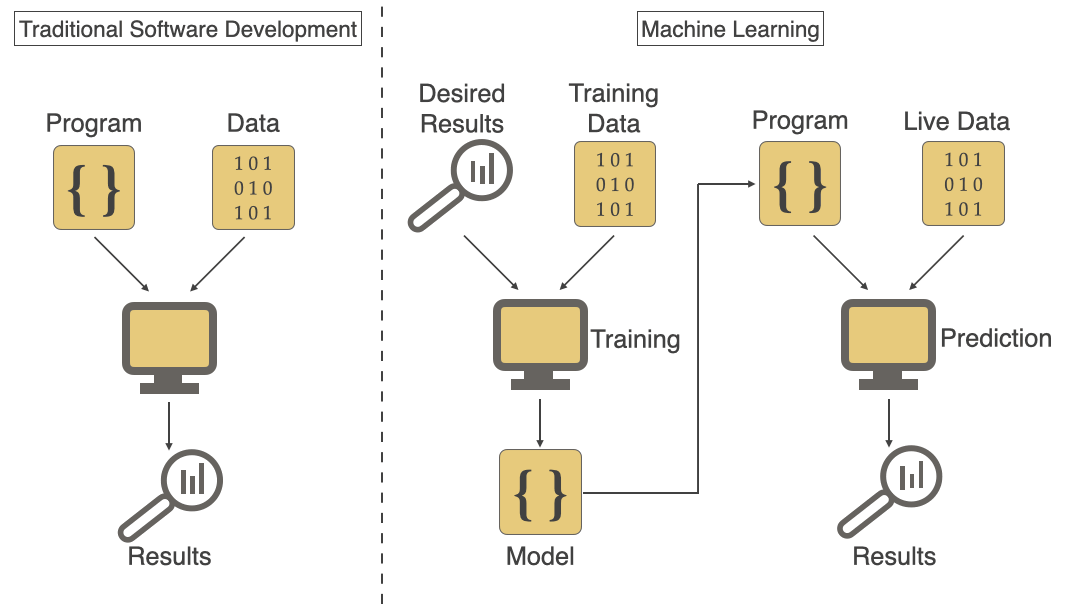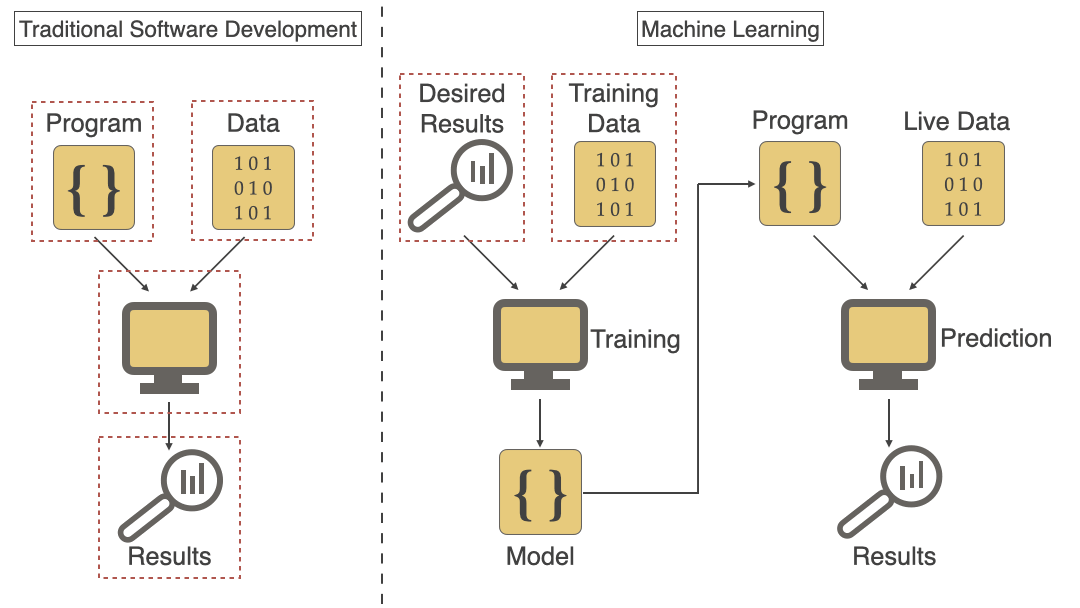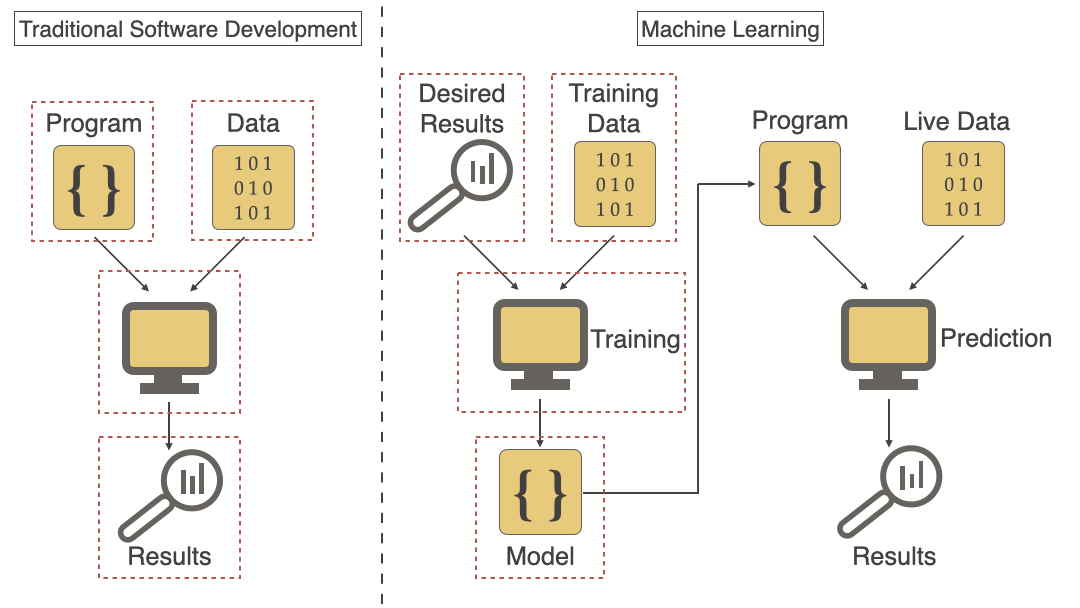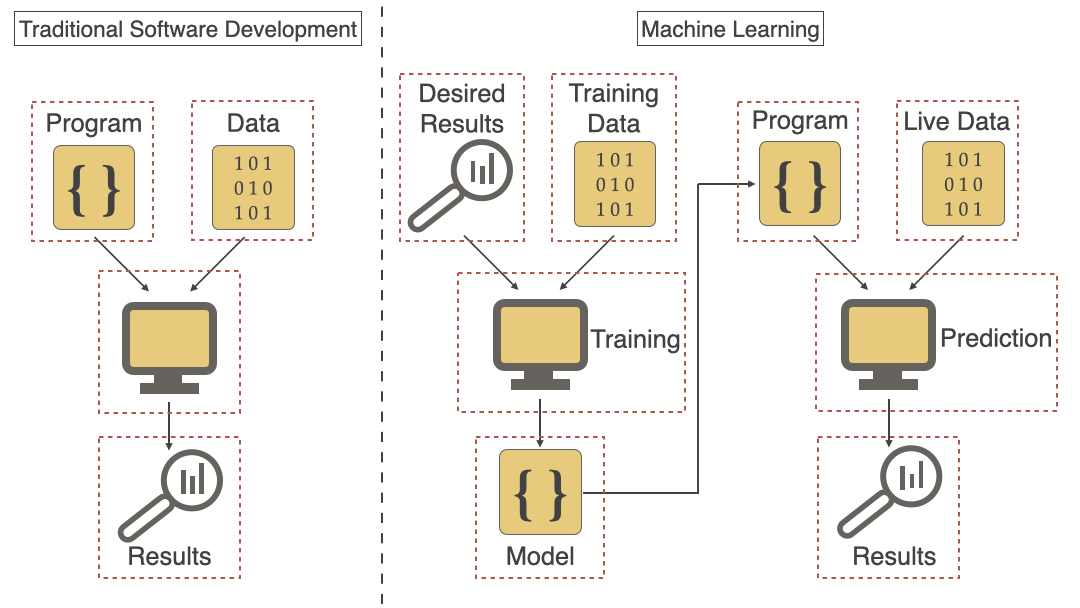
Traditional Software Development vs Machine Learning
If you were to think of traditional software development in juxtaposition with Machine Learning, you can very clearly see where the latter diverges in diagram #2 below. Even though that’s the case most of the principles and practices of traditional software development can be applied to Machine Learning but there are certain unique ML specific challenges that need to be handled differently. We will talk about those unique challenges that make it difficult to deploy ML models to production in this article.
Machine Learning Workflow
Typical ML workflow includes Data Management, Experimentation, and Production Deployment as seen in the workflow below.
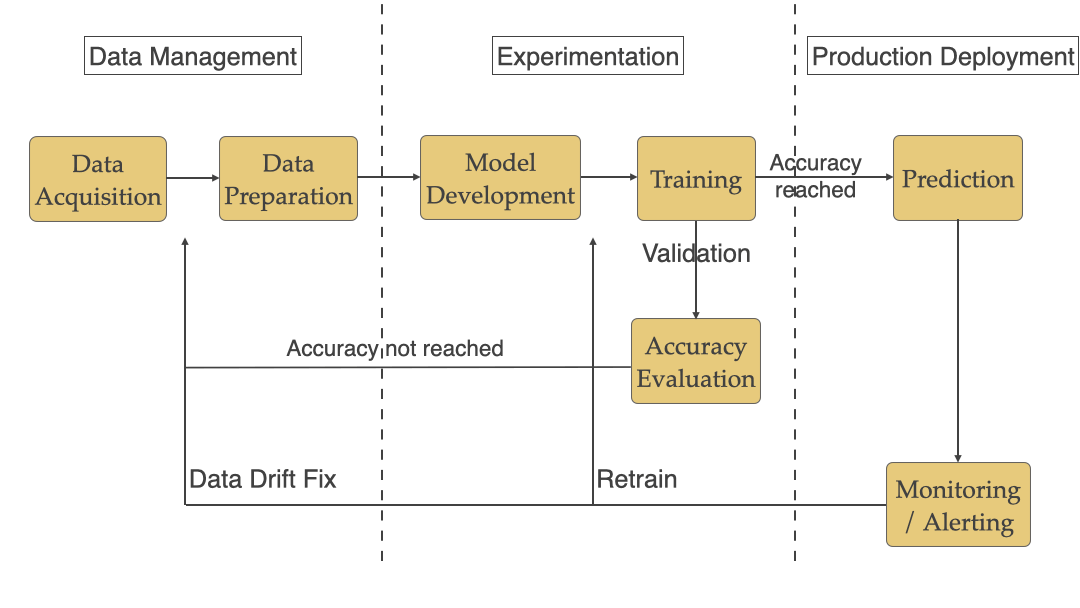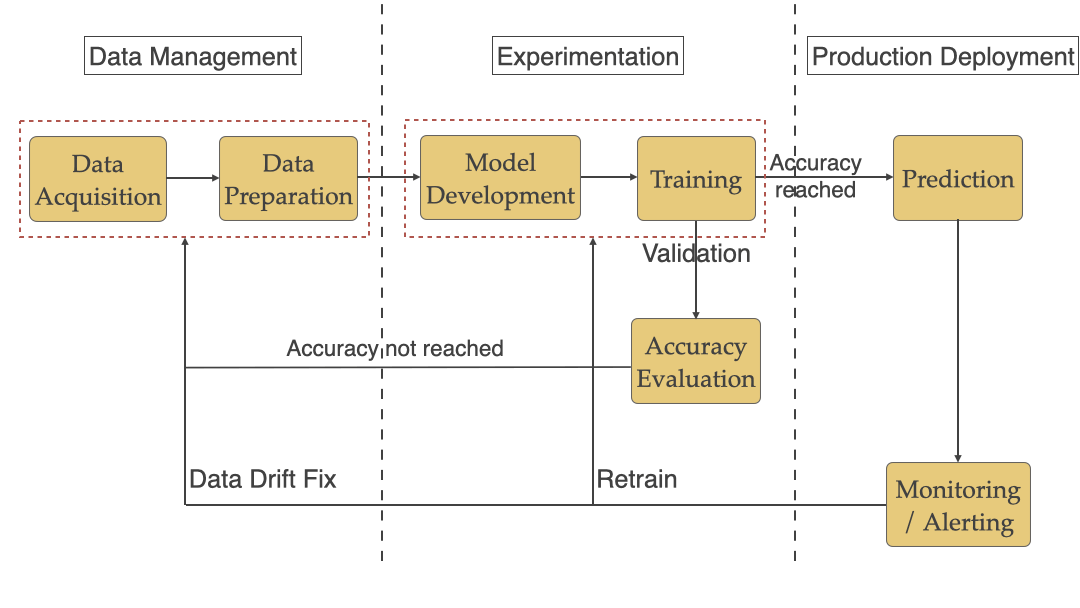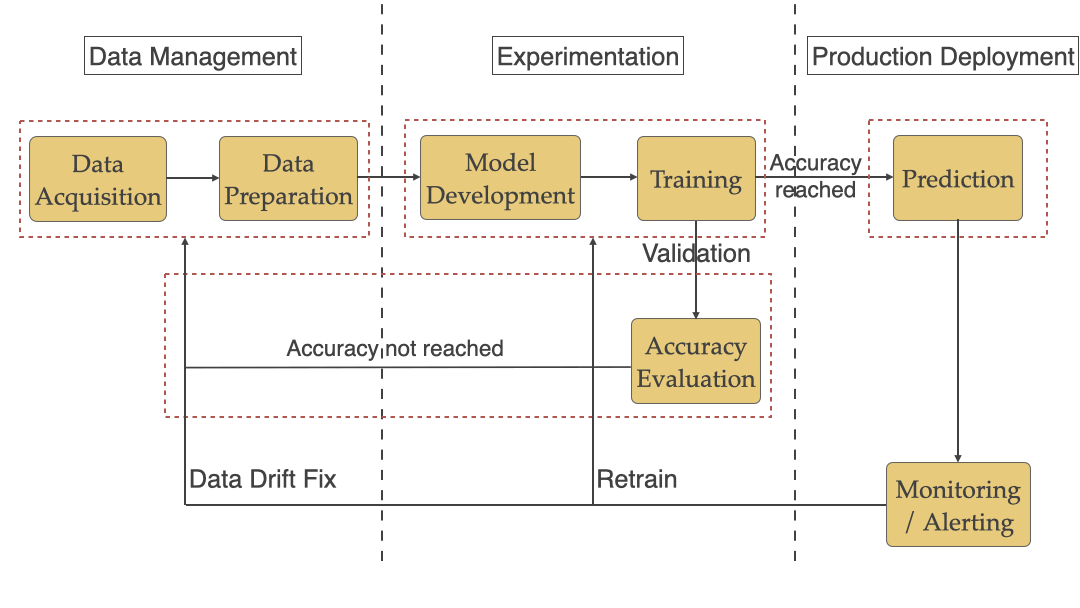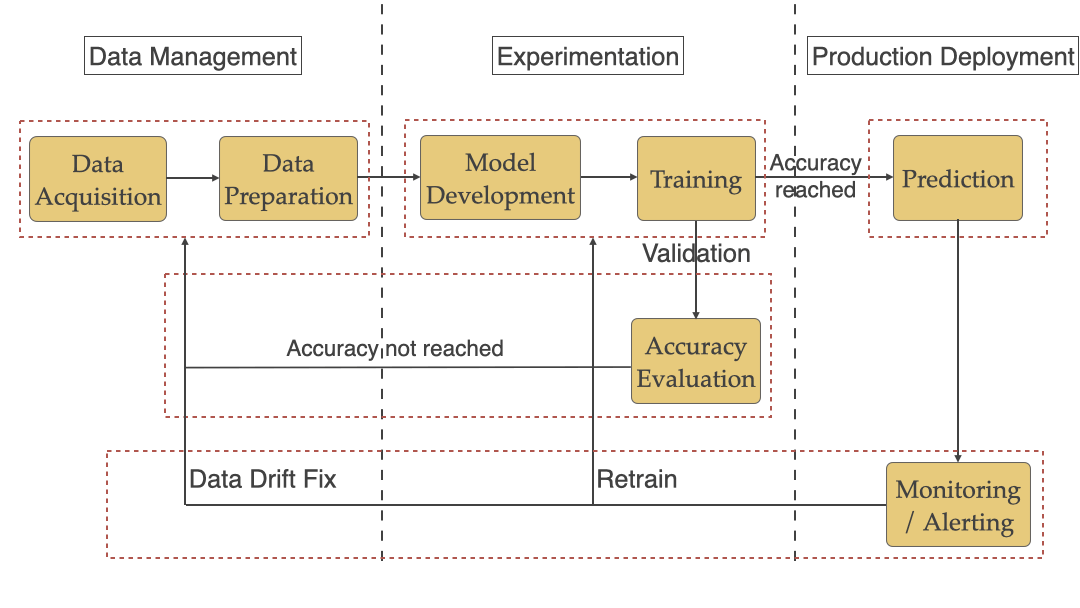
We will be looking at each stage below and the ML specific challenges that teams face with each of them.
Stage #1: Data Management
Training data is one of the fundamental factors that determine how well a model performs. This stage typically includes data acquisition and preparation. You need to be aware of the following challenges while working with ML data:
Large Data Size: Models usually need large datasets during the training process to improve its accuracy during prediction against live data. Datasets can be in hundreds of Gigabytes or even larger. This brings up some unique challenges like moving around data is not as easy and there is usually a heavy cost associated with data transfer and is time-consuming.
High-Quality Data: Having a large dataset is of no use if the quality of data is bad. Finding the right data of high quality is pretty important for model accuracy. Fetching data from the correct source and having enough validation to make sure that the quality is high helps the cause. Making sure your Model is not biased based on aspects like Race, Gender, Age, Income Groups, etc. is critical too. For that, you need to make sure you have Model Bias and Fairness Validation of your data.
Dataset Tracking: Replicating how the model was trained is helpful for data scientists. For that, the dataset that was used during each training run needs to be versioned and tracked. This also gives data scientists the flexibility to go back to a previous version of the dataset and analyze it.
Location: Depending on the use case these datasets reside at various locations and as mentioned above they might be of larger size. Because of these reasons, it might make sense to run the training and in some cases prediction closer to where the data is instead of transferring large data sets across locations.
Caution: Make sure this is worth the effort. If you can manage without adding this complexity and run things centrally I would recommend you do that.
Security & Compliance: In some cases, data being used might be sensitive or need to meet certain compliance standards (like HIPAA, PCI, or GDPR). You need to keep this in mind when you are supporting ML systems.
Stage #2: Experimentation
This stage includes Model development where Data Scientists focus a lot of their time researching various architectures to see what fits their needs. For example, for Semantic Segmentation here are various architectures available. Data Scientists write code to use the data from the previous stage and use that to train the model and then do an evaluation to see if it meets the accuracy standards they are looking for. See below some of the challenges that you will face during this stage.
Constant Research and Experimentation Workflow: They spend time collecting/generating data, experimenting, and trying out various architectures to see what works for their use case. They also try hyperparameter optimization and training with various datasets to see what gives more accurate results.
Due to the research and experimental nature of this, the workflow that needs to be supported is different from traditional software development.
Tracking Experiments: One of the key aspects of this workflow is to allow data scientists to track experiments and know what changed between various runs. They should easily be able to track dataset, architecture, code, and hyper-parameter changes between various experiments.
Code Quality: Due to the research and experimentation phase a lot of code written is usually not of high quality and not ready for production. Data Scientists spend a lot of time working with tools like Jupyter Notebook and making changes there directly to test out. You need to keep this in mind and handle it before deploying ML models to production.
Training Time & Troubleshooting: Training a model typically requires hours or sometimes days to run and needs special infrastructure(see challenge #4 below). For example, a full build of Tesla Autopilot neural networks takes 70,000 GPU hours to train as per their website. Since training typically takes a lot of time you need to be able to support easy troubleshooting using aspects like monitoring, logging, alerting, and validation during the training process. If the training process errors out, providing easy ways of fixing the issue, and continuing/restarting the training is important.
Model Accuracy Evaluation: After training the model accuracy needs to be evaluated to see if it meets the standard required for prediction in production. As seen in diagram #3 above you reiterate through the training/data management steps to keep improving the accuracy until you reach an acceptable number.
Retraining: In cases when you have a data drift, a bug in production, or change in requirements you might need to retrain the model. There needs to be a way to support retraining models.
Infrastructure Requirements: ML workloads have certain special Infrastructure requirements like GPU & High-Density Cores. Thousands of processing cores run simultaneously in a GPU which enables training and prediction to run much faster compared to just CPUs. Since these infrastructure requirements (especially GPU) are costly and are needed mostly in periodic bursts for training, having support for elasticity and automation to scale as well as provision/de-provision infrastructure (especially when using the cloud) is a good idea.
Edge Devices (IoT, mobile, etc) like the Nvidia Jetson series are more and more used these days, and deploying to these devices is another challenge as these devices mostly use ARM architecture instead of x86 that have limited resources. Models need to be tested on these devices for accuracy as well as performance.
Due to lack of support for certain dependencies and their latest versions for the ARM architecture having good practices around building packages/models helps.
Stage #3: Production Deployment
After the model is trained and reaches certain accuracy it gets deployed to production where it starts making predictions against live data. Here are some challenges to be aware of for this stage.
Offline/Online Prediction: Depending on the model and the way it is going to be used in production with live data you might have to support either offline (batch) prediction or online (real-time) prediction. You need an appropriate framework to serve the model based on the type (batch or real-time). If it’s a batch prediction make sure you can schedule the batch job appropriately and for real-time, you need to worry about processing time since the result is usually needed back synchronously.
Model Degradation: Model degrades (i.e. Predictions become less accurate) in Production due to various factors like data drift, environment changes, etc. over time. It’s essential to have the information necessary to troubleshoot & fix a problem readily available to the teams so they can act on it.
Conclusion
DevOps Principles and Practices that include all 3 aspects (People, Process & Technology) have been used effectively for mitigating challenges with traditional software. These same DevOps Principles and Practices along with some Machine Learning specific practices can be used for deploying & operating ML Systems successfully. These ML principles and practices are also known as MLOps or DevOps for Machine Learning. I will be writing follow-up articles that will look at those principles and practices that help overcome the challenges mentioned in this article.
Acknowledgments: Priyanka Rao and Bobby Wagner read the draft version of this article and provided feedback to improve it.