Deploying Machine Learning Systems to Production safely and quickly in a sustainable way
Table of Contents
Most of the principles and practices of traditional software development can be applied to Machine Learning(ML), but certain unique ML specific challenges need to be handled differently. We discussed those unique “Challenges Deploying Machine Learning Models to Production” in the previous article. This article will look at how Continuous Delivery that has helped traditional software solve its deployment challenges be applied to Machine Learning.
What is Continuous Delivery?
Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes, and experiments—into production, or into the hands of users, safely and quickly, in a sustainable way.
– Jez Humble and Dave Farley
(Continuous Delivery Book Authors)
Below are the Continuous Delivery Principles defined in the book, and you can read more about it here.
- Build quality in
- Work in small batches
- Computers perform repetitive tasks, people solve problems
- Relentlessly pursue continuous improvement (Kaizen)
- Everyone is responsible
Continuous Integration
Continuous Integration (CI) should be the first step for teams starting the Continuous Delivery journey. As you can see in the definition below, CI helps find any integration errors as quickly as possible, thereby increasing team productivity.
Continuous Integration is a software development practice where members of a team integrate their work frequently, usually, each person integrates at least daily – leading to multiple integrations per day. Each integration is verified by an automated build (including test) to detect integration errors as quickly as possible.
– Martin Fowler
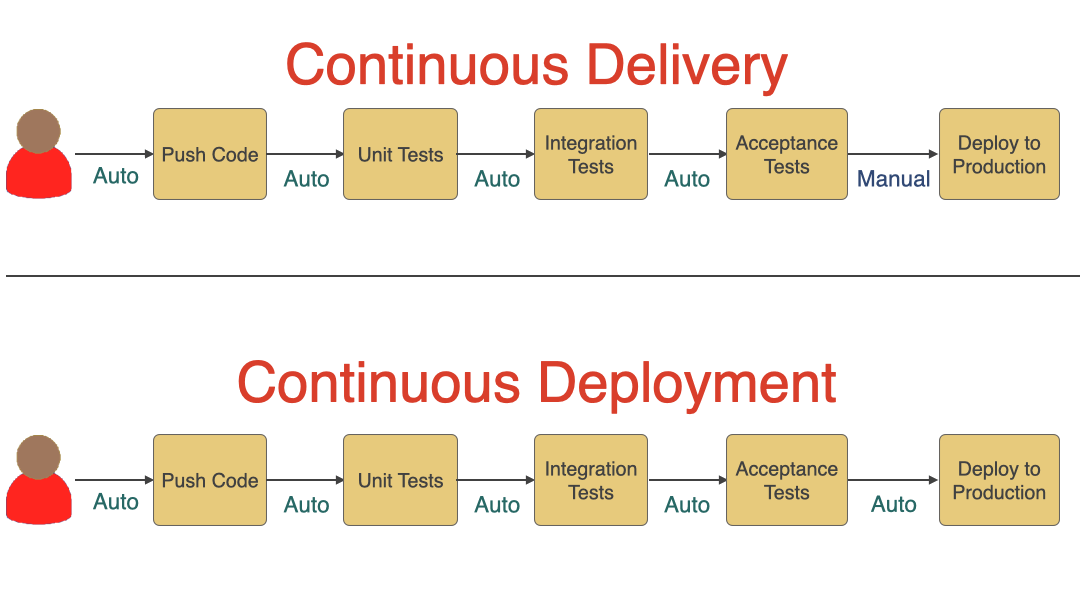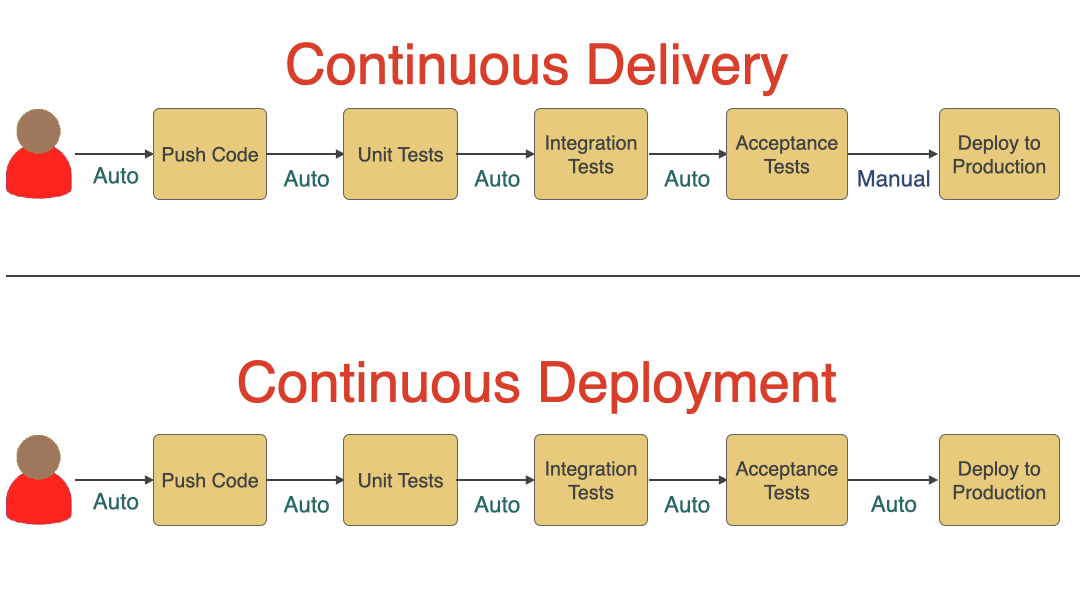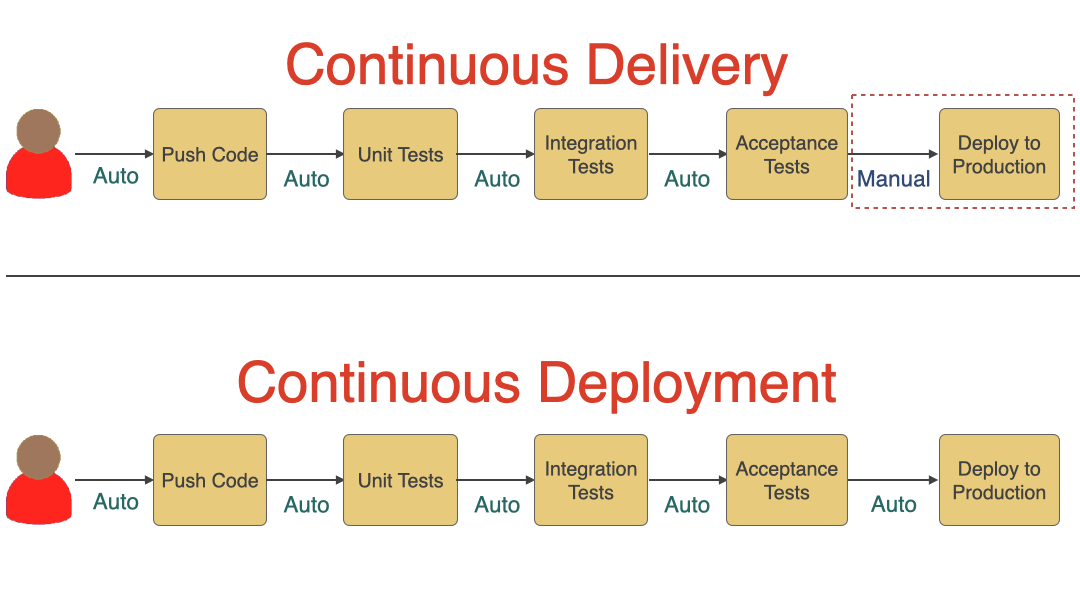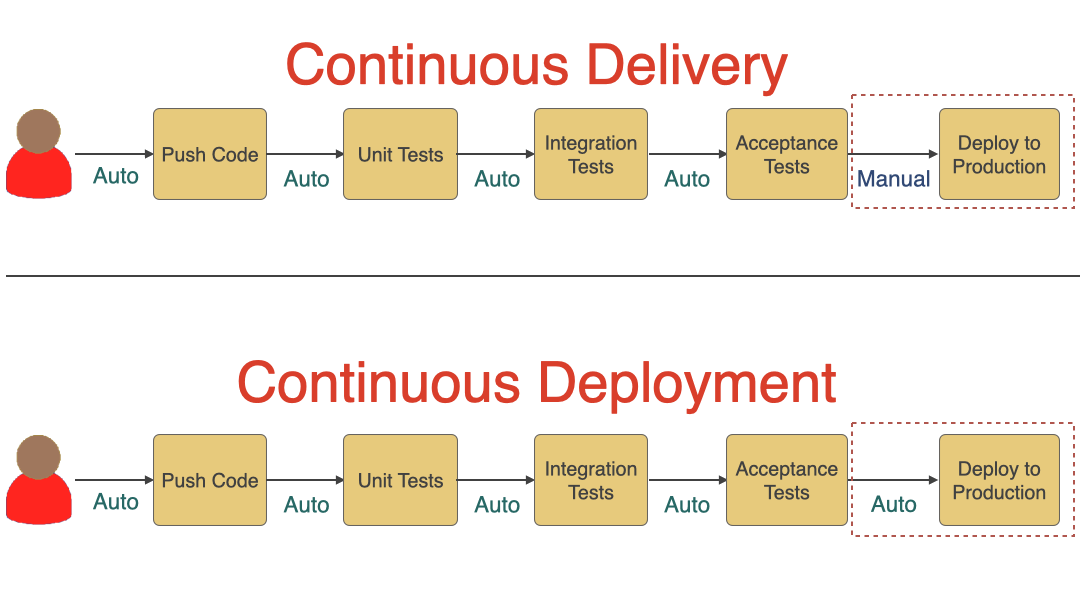
Continuous Delivery vs. Continuous Deployment
We won’t be talking much about Continuous Deployment in this article, but it is good to understand the difference between Continuous Delivery and Continuous Deployment. As you can see in the diagram below, Continuous Delivery includes a manual approval step before deploying to production. Still, every time code is pushed to the main branch, it goes through various automated steps and is ready for deployment. Meanwhile, if all the steps succeed, it automatically deploys the new code to production in case of continuous deployment.
Machine Learning Workflow
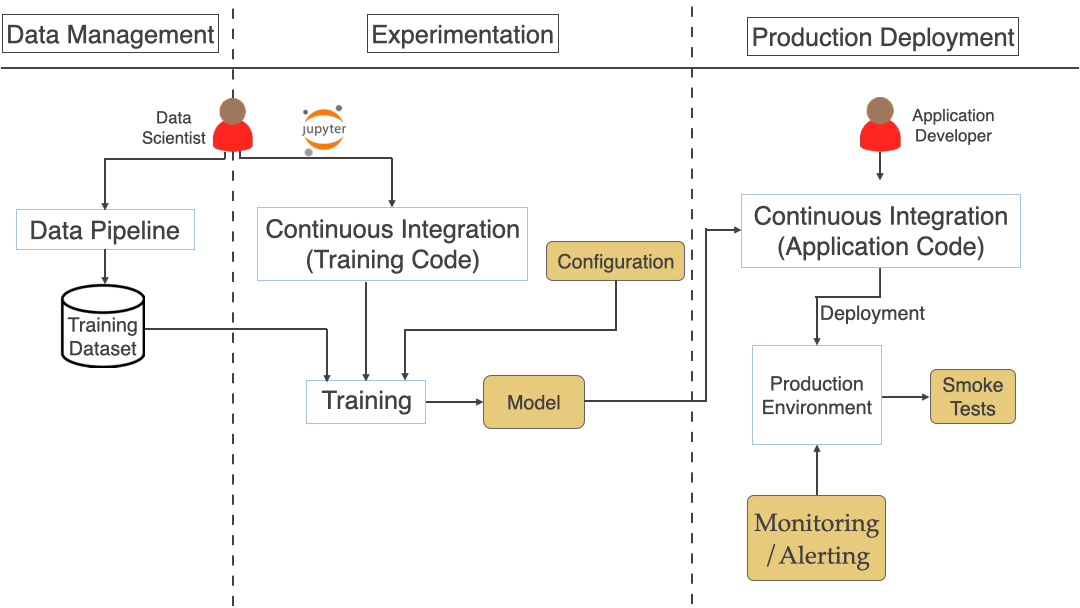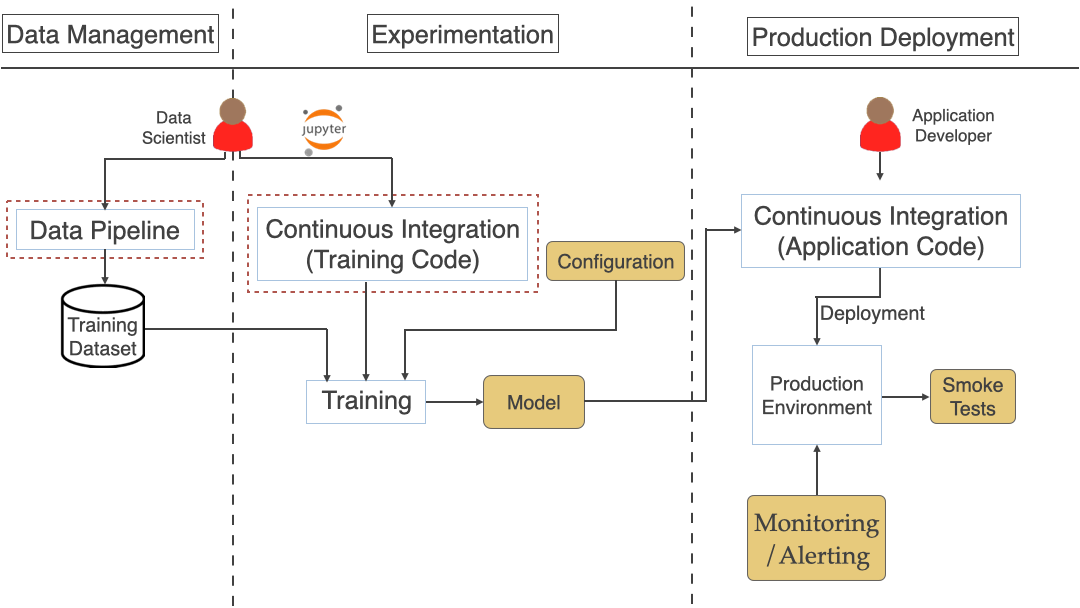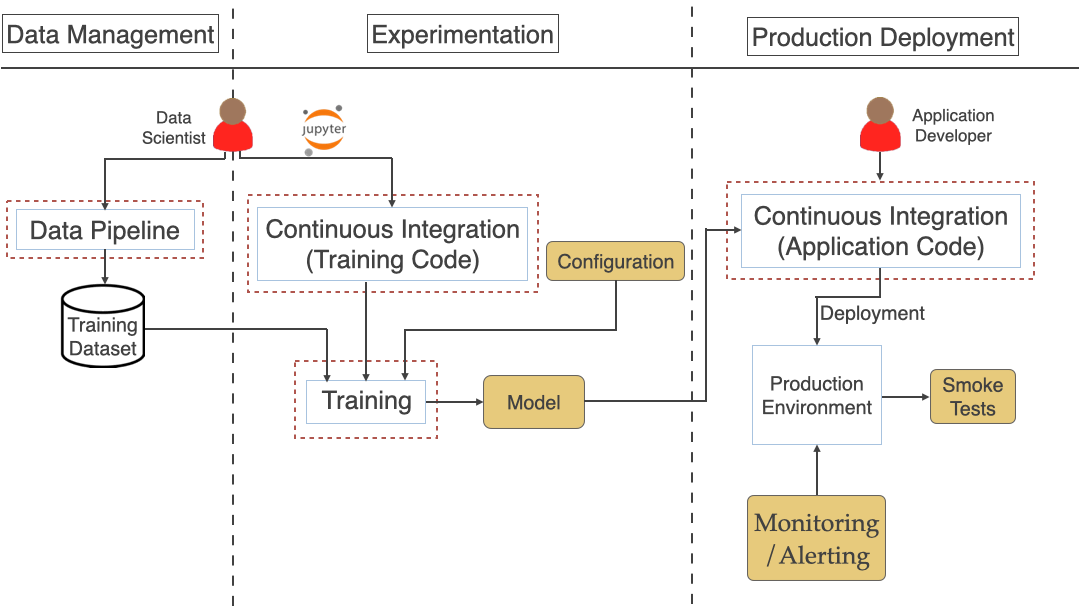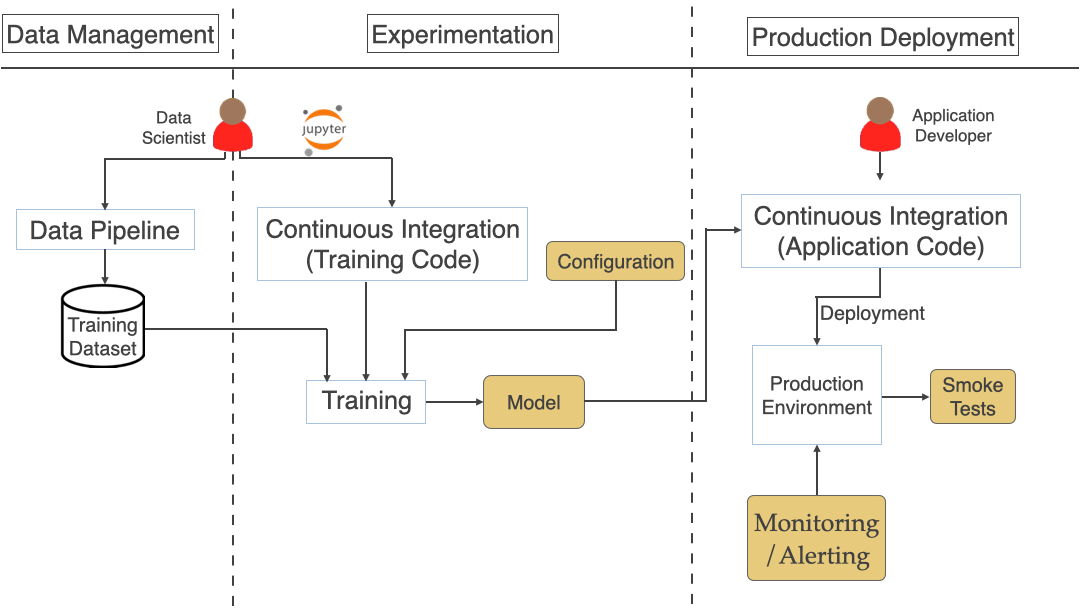
As we saw in the previous article, a typical ML workflow includes Data Management, Experimentation, and Production Deployment shown in the diagram below. We broke down the challenges by these 3 phases.
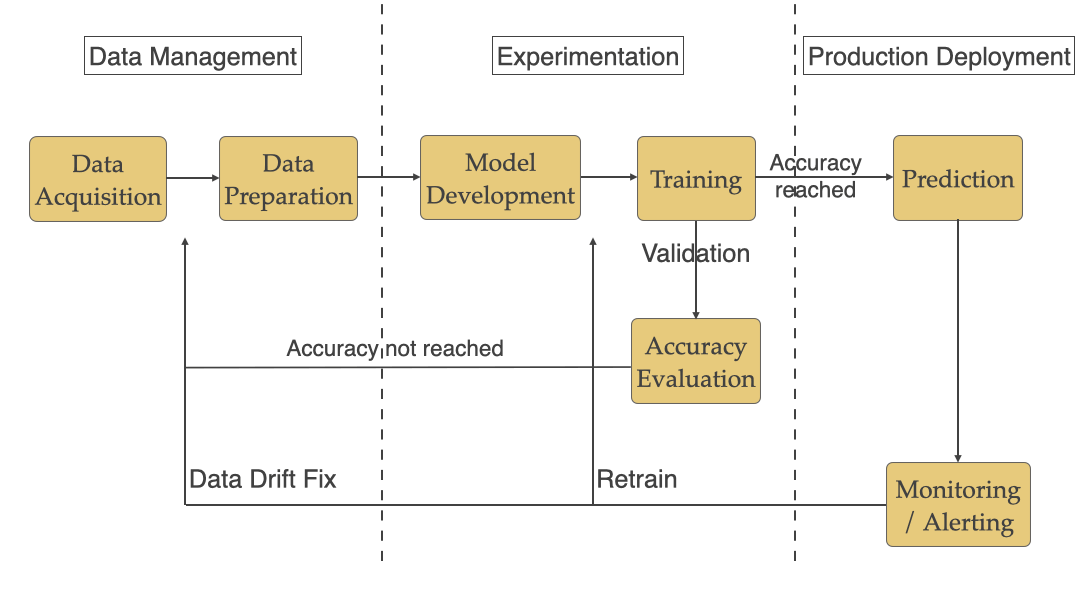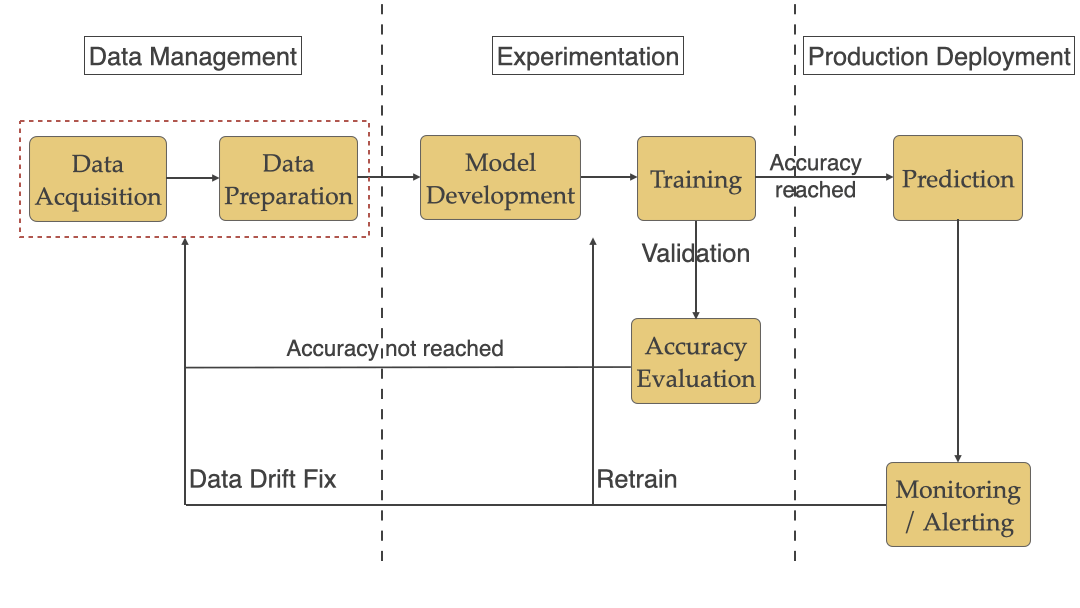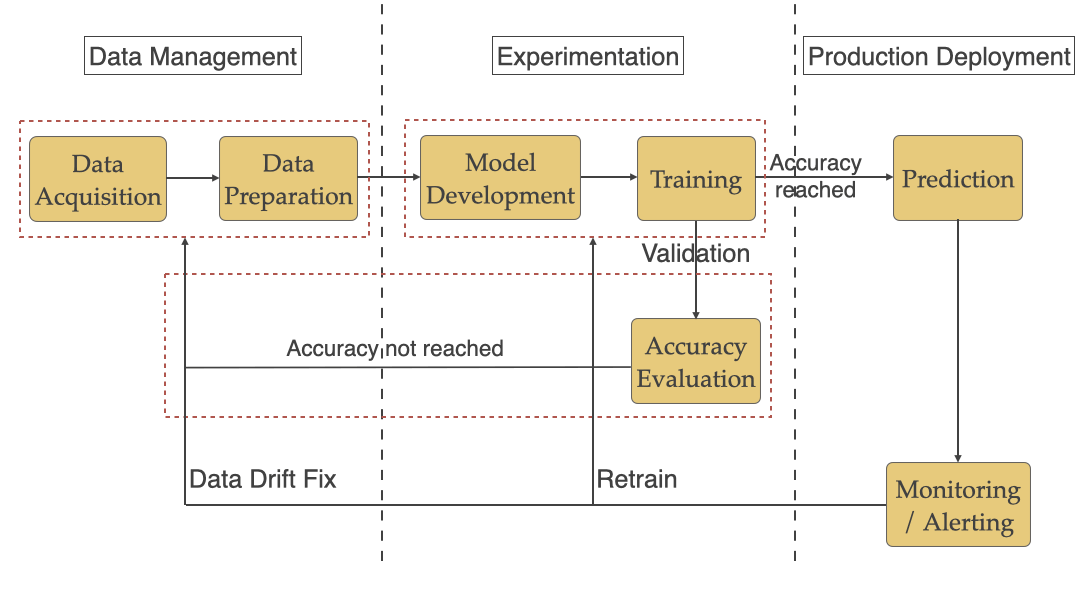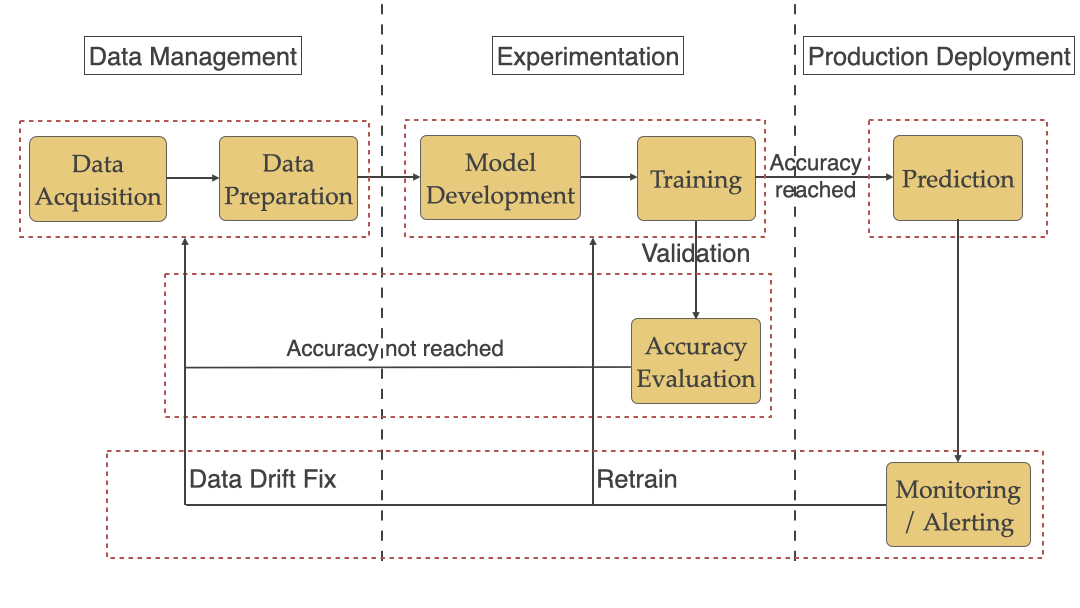
How does Continuous Delivery help with ML challenges?
Now let’s look at how Continuous Delivery can help resolve Machine Learning specific Challenges. We will go over each phase of ML workflow, its challenges, and how CD can resolve them.
Data Management
The training dataset is the output of the Data Management phase that then feeds into the training process. It is one of the fundamental factors that determine how well a model performs. This stage typically includes data acquisition and preparation. Adding an automated data pipeline for the generation of training dataset helps solve most of the challenges during this phase.
Automated Data Pipeline
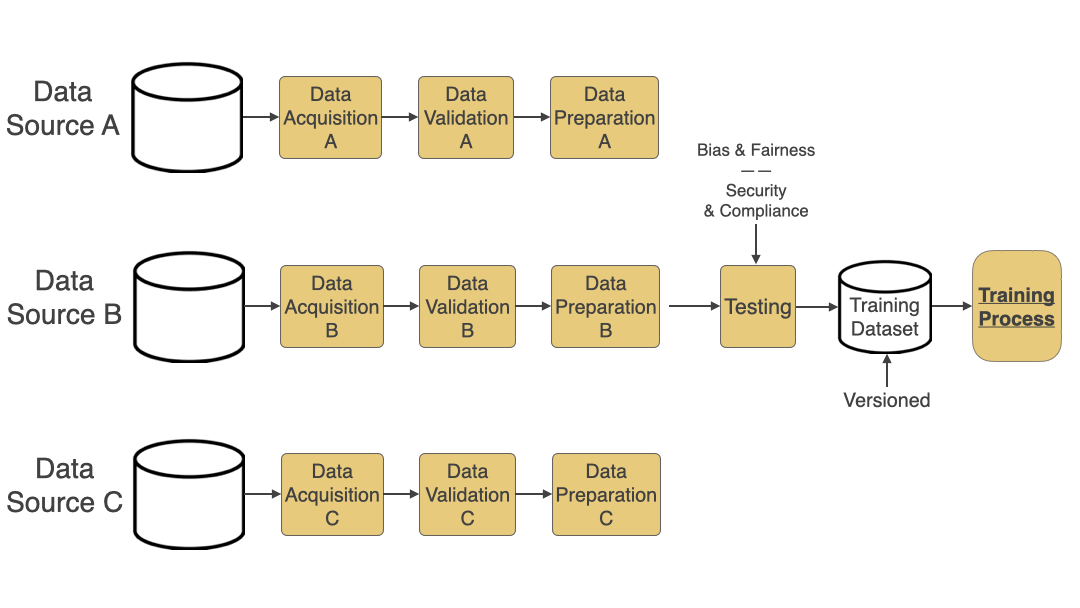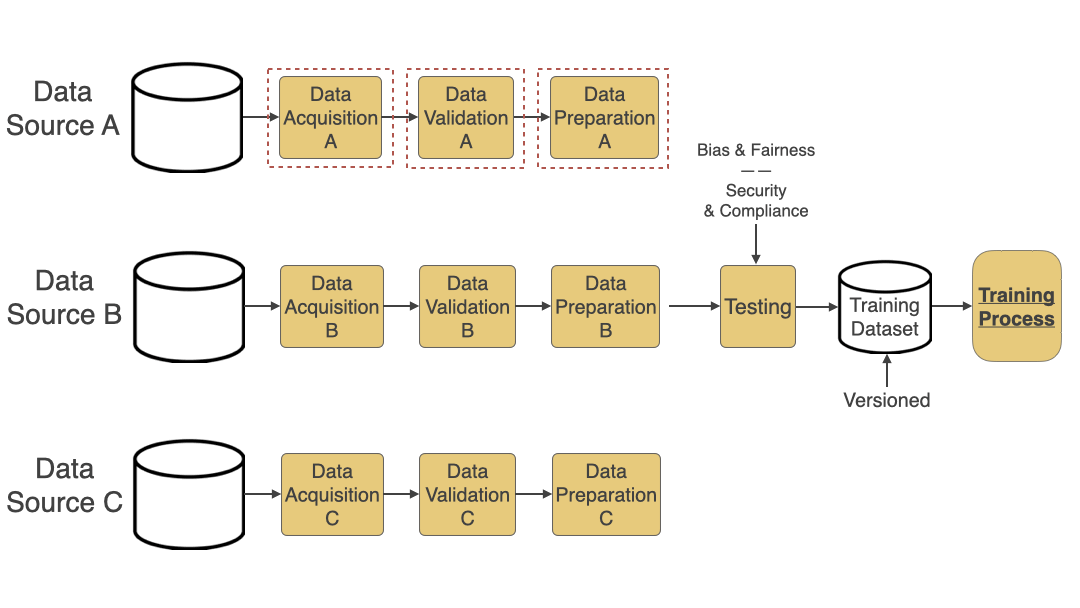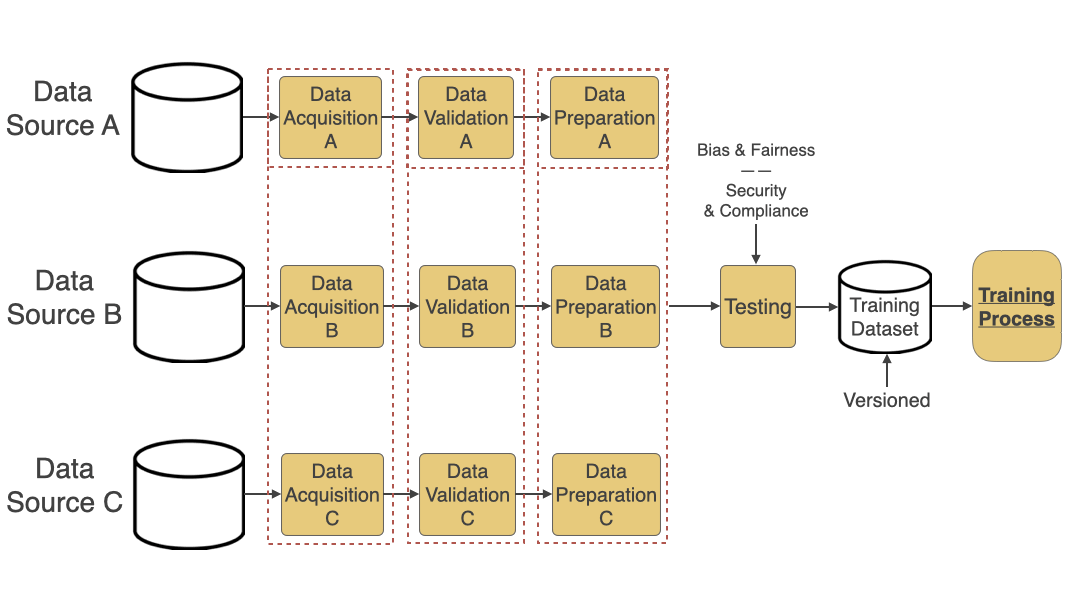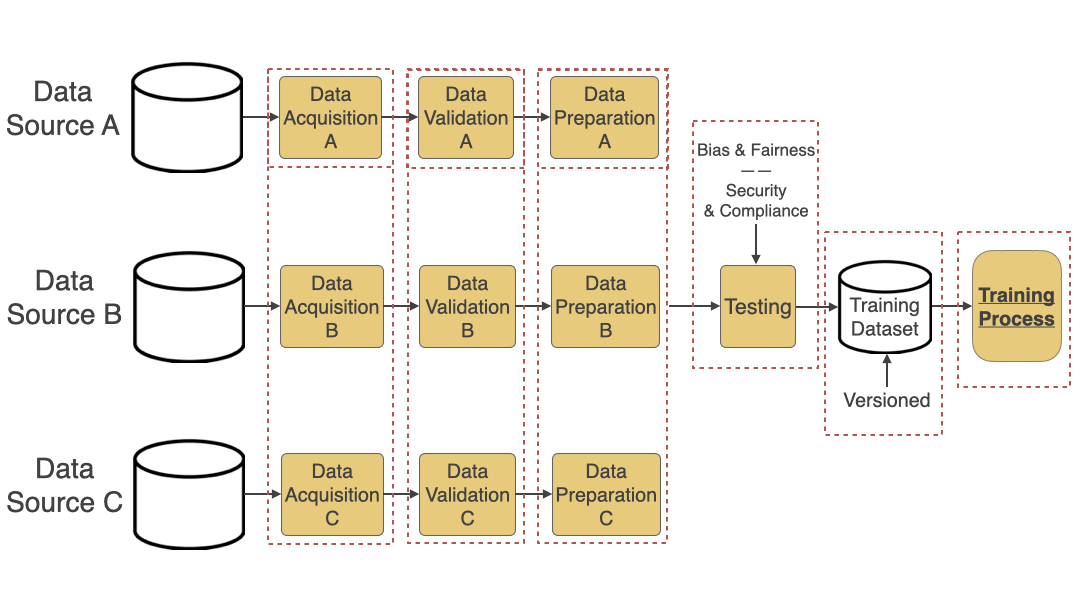
An automated data pipeline includes the following steps:
- Data Acquisition: Acquire data from various sources like S3 buckets, public datasets, etc. One of the ways to do this efficiently is to use the Adapter Pattern.
- Data Validation: Validate data schema and other types of validation needed for better quality data.
- Data Preparation: Based on the validation and for the data to be ready for the training process, this step does normalization, transformation, feature extraction, etc.
- Data Testing: This step is often overlooked but is very important. Add Bias and Fairness Testing to ensure bias is not introduced in the model through data is critical. Also, add automated tests to ensure that the data acquired is secure and compliant (based on the regulations you need to adhere to like HIPAA, PCI, or GDPR).
- Data Versioning: Add a step to version the training dataset generated so you can easily go back to a specific version and track changes. Versioning helps when you are mainly experimenting with various architectures or training your models and want to compare the accuracy results of multiple runs against multiple versions of your dataset.
See below the challenges defined in the previous article & how adding an automated data pipeline helps solve the challenges. You can read more about the challenges here.
Challenge: Large Data Size
Solution: Since model training usually requires large data sets, it is time-consuming & costly to process it manually. Having an automated data pipeline like mentioned above, makes the process repeatable and saves a lot of time and reduces the chances of having data issues.
Challenge: High-Quality Data
Solution: Adding automated Data Validation and Testing for things like Bias and Fairness, plus Security and Compliance, helps ensure the data is of high quality, which helps produce better models.
Challenge: Dataset Tracking
Solution: Keeping track of experiments and training helps compare various training runs to see what works and what doesn’t. Versioning data helps in tracking which dataset gives you better results. As you can see in the diagram above, there should be a step to the version dataset. There are tools like dvc available that provide version control for data.
Challenge: Location
Solution: When datasets reside in various locations, and it might not make sense to transfer it due to large size, transfer costs, or compliance reasons, it makes sense to run data pipeline, training, or even prediction closer to where the data resides. Having an automated pipeline for these that can easily be run anywhere with minimum effort helps in those cases.
Caution: Make sure this is worth the effort. If you can manage without adding this complexity and run things centrally, I recommend you do that.
Challenge: Security and Compliance
Solution: As seen in the diagram above, to ensure data is secure and compliant, add automated security and compliance tests in your data pipelines.
Experimentation
This stage includes Model development, where Data Scientists focus a lot of their time researching various architectures to see what fits their needs. They need to write the Training Code and use the Training Dataset generated from the Data Management phase and configuration to train the model.
Training Code
Even though this is a training code and not a production code having continuous integration for the code helps find issues faster. Due to the research and experimentation phase, a lot of code written is usually not of high quality, but adding things like Static analysis and Unit testing will help find any issues faster and provide faster feedback. At the end of CI for training code, there should be a versioned artifact generated (docker image, zip file, etc.) that will then be used to train the model. Since this is an experimentation phase, there might be a lot of changes happening. Still, I would highly encourage you to merge changes frequently to the main branch and run CI. Use of techniques like feature toggles or versioning the artifact as alpha, beta, or release helps identify artifacts that can be used in the training process.
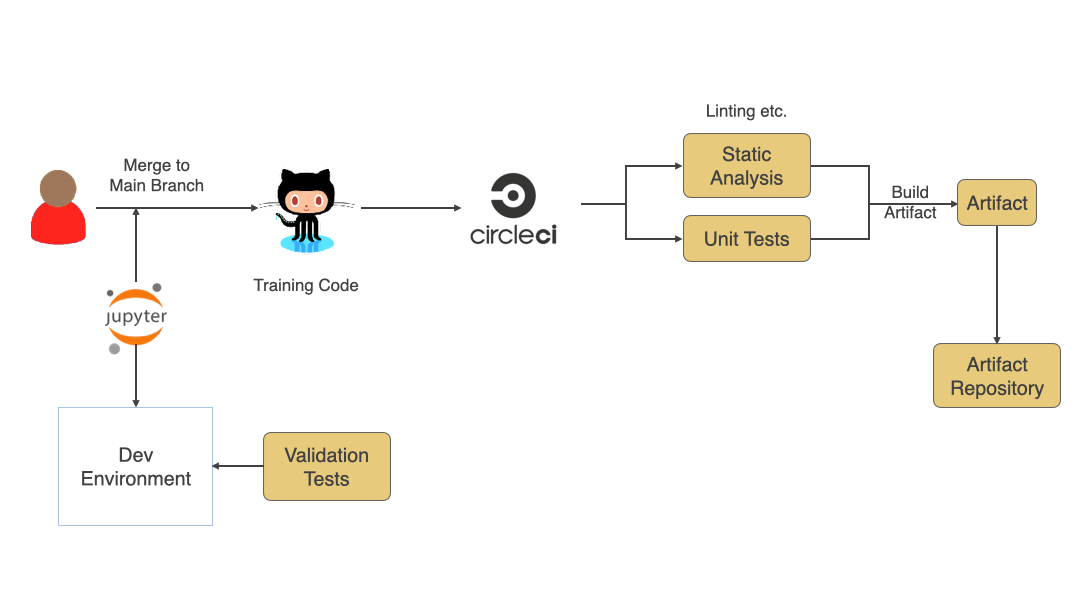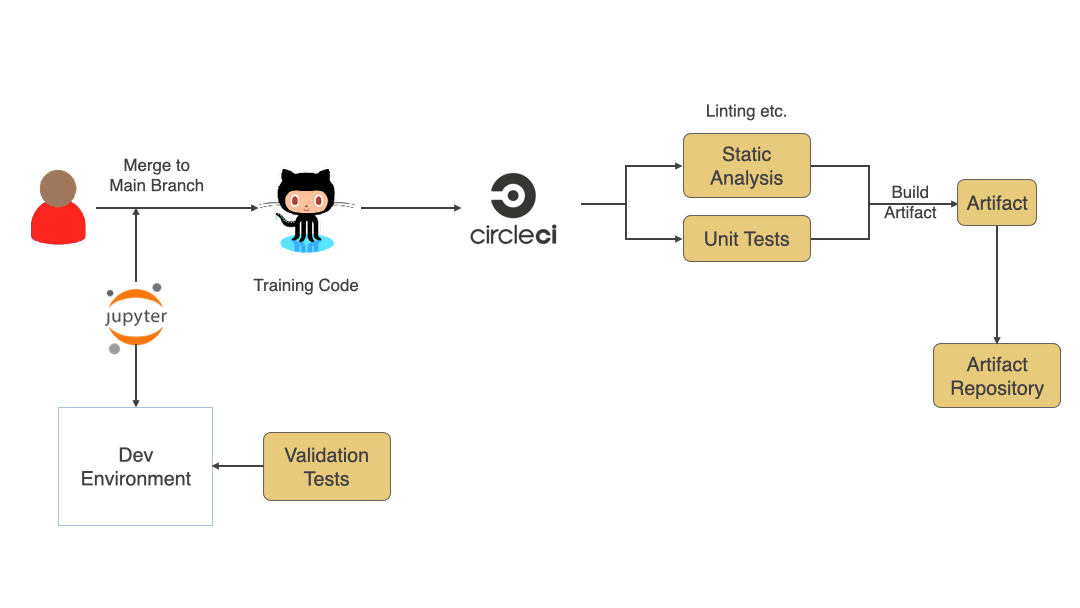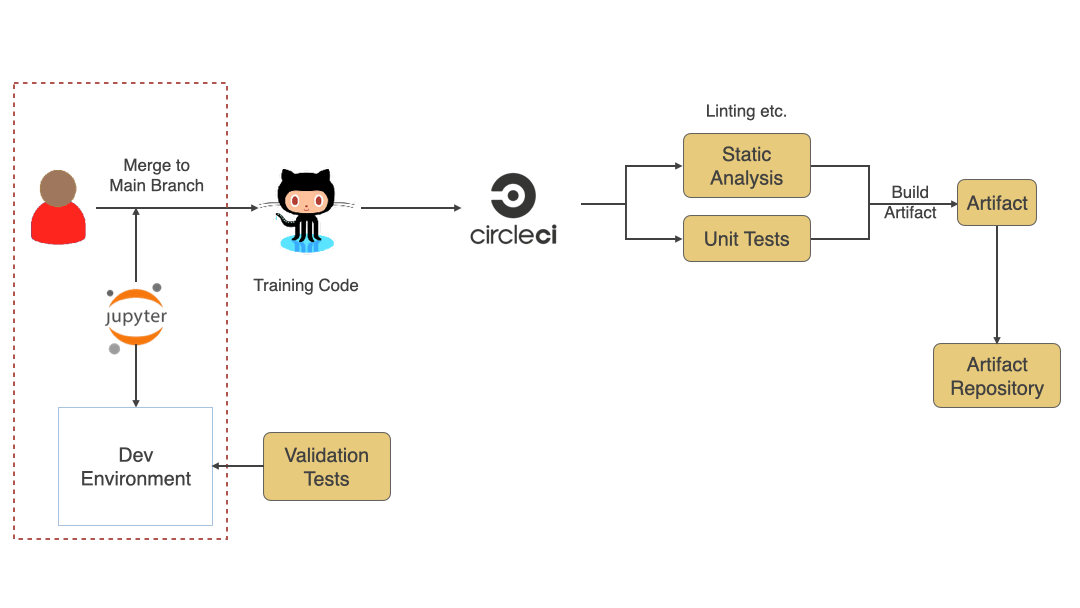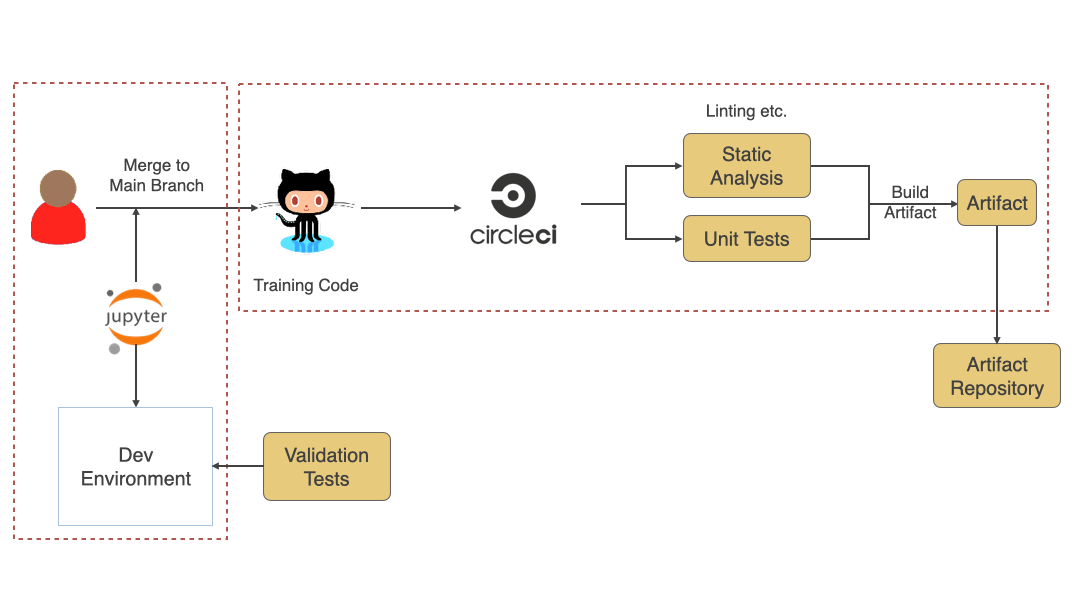
Training Process
See below (in diagram #5) typical training process and various pieces involved. Training Dataset generated in the previous phase and the Training Code written during the last step, and any training environment configuration is used as an input to the training process. Data Scientists trigger the training process, which might run for hours or days. After its completed, automated accuracy evaluation should be added to see whether the model meets expected standards. Adding a Bias and Fairness testing step here also helps make sure the model is fair when it will run in Production against live data. If everything goes well, the model should be versioned and stored in an artifact repository to be fetched during deployment to production.
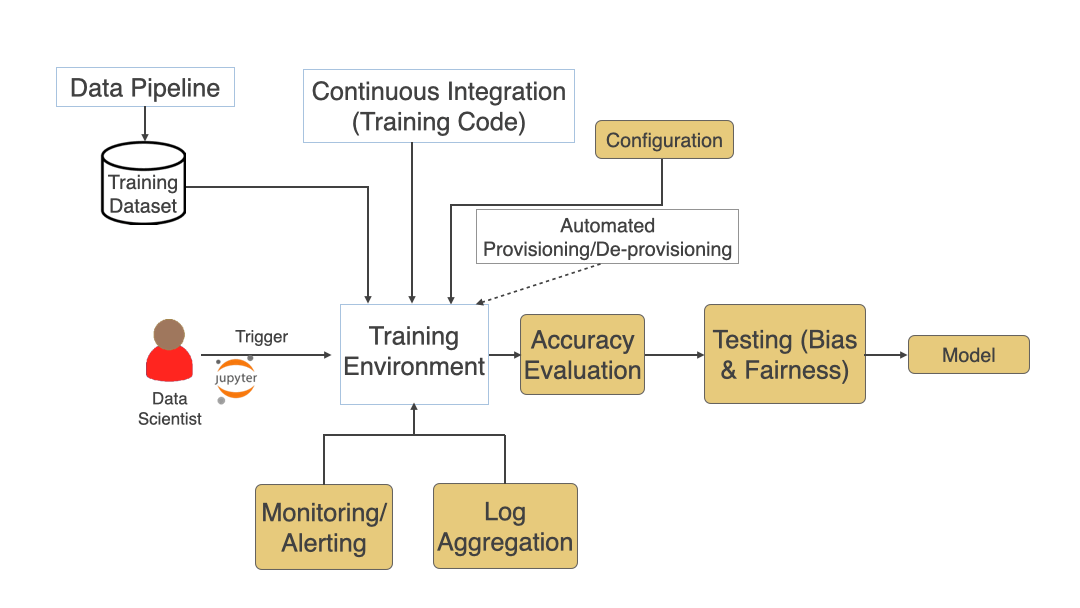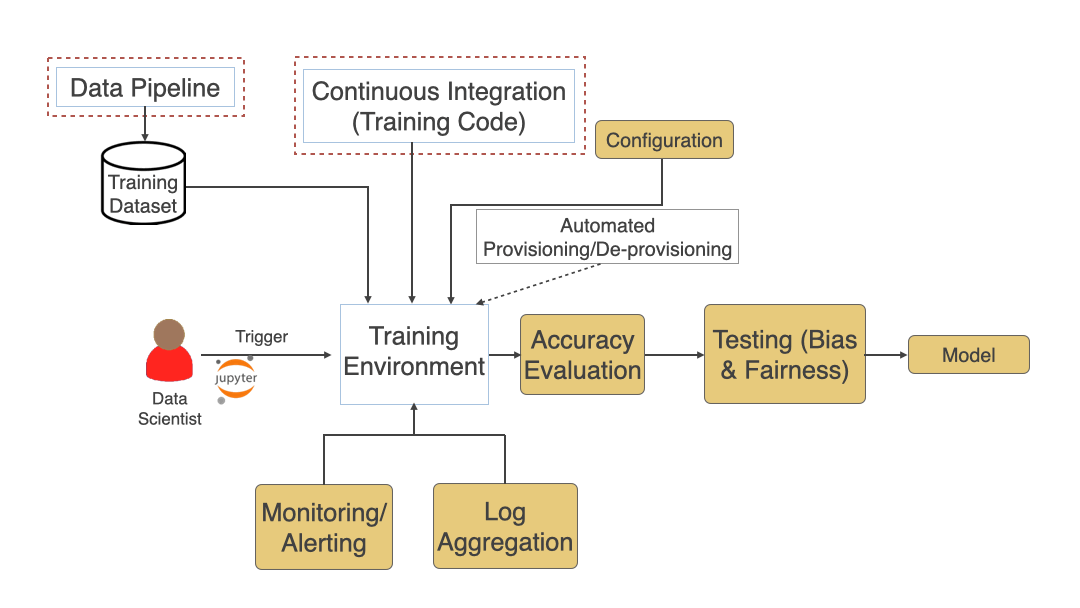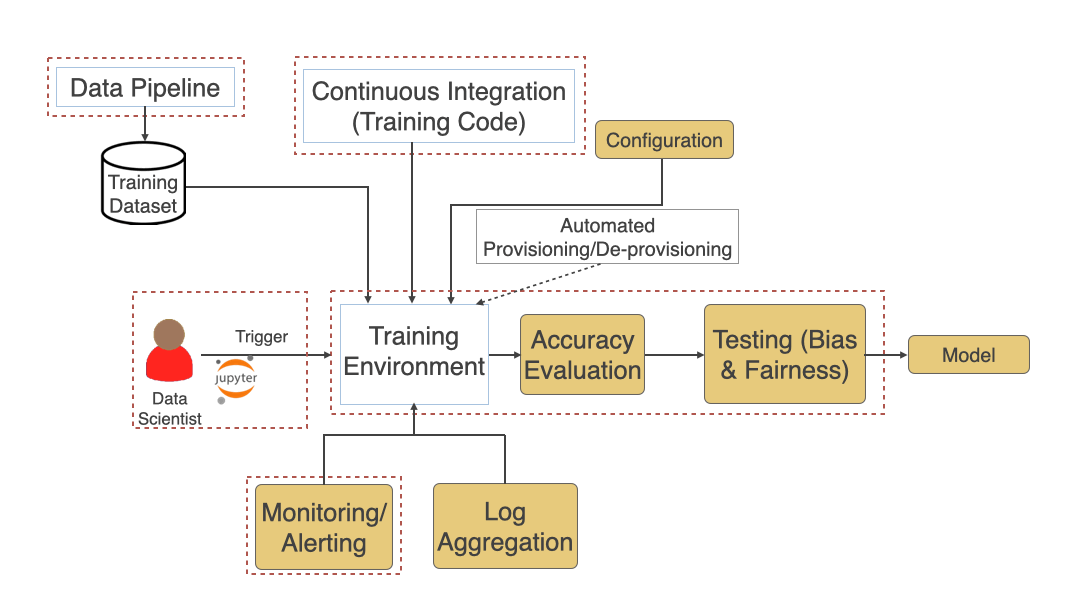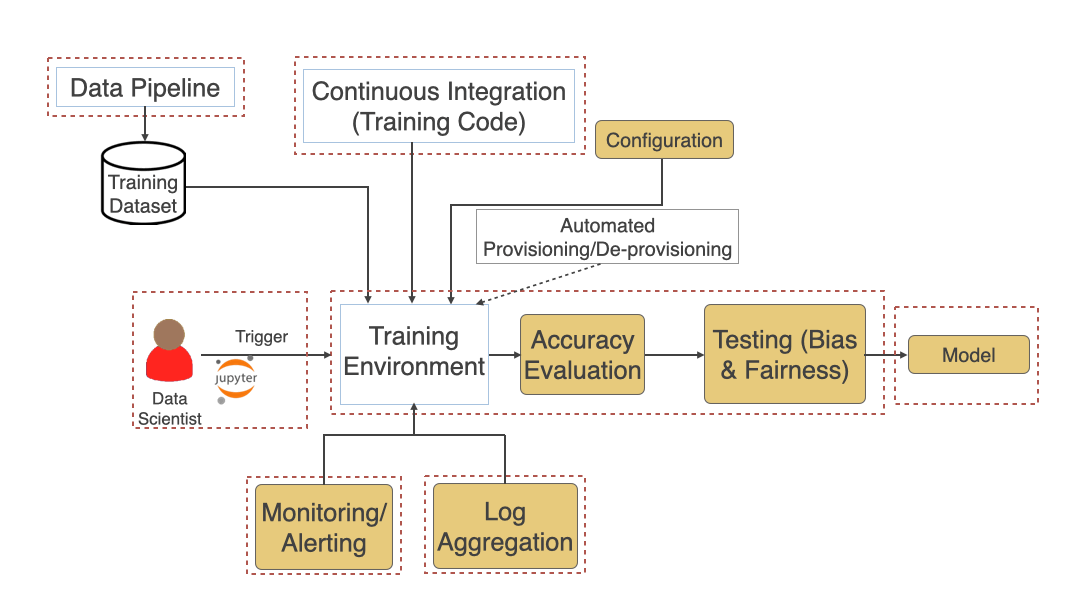
Challenges that you can read about more here:
Challenge: Constant Research and Experimentation Workflow
Solution: Adding CI for Training Code and making sure that the training code, training dataset, and the model generated are versioned helps in finding issues faster and tracking any changes made. As mentioned above, even though there are usually many changes happening during this phase, I would highly encourage to merge changes frequently to the main branch and run CI.
Challenge: Tracking Experiments
Solution: By tracking various components of the training process like training dataset, training code, model, etc. we can easily reproduce results and track experiments.
Challenge: Code Quality
Solution: Adding CI and automated tests help improve code quality as issues can be found sooner and fixed.
Challenge: Training Time and Troubleshooting
Solution: Since Training usually takes hours or even days having automation to find issues faster and appropriate monitoring, alerting & log aggregation helps in troubleshooting those issues better.
Challenge: Model Accuracy Evaluation
Solution: Adding a step to automatically evaluate model accuracy enables a comparison between various runs and picking the best performing model for production deployment.
Challenge: Retraining
Solution: Often, when there is a data drift or changes in logic, models need to be retrained. For that, having the automation mentioned above helps.
Challenge: Infrastructure Requirements
Solution: Training and sometimes prediction has certain special Infrastructure requirements like GPU & High-Density Cores. These are usually costly and are only needed in periodic bursts. Having automation using Infrastructure as Code to provision/de-provision infrastructure (especially when using the cloud) reduces the cost and reduces issues that come with long-lived infrastructure. For more info, read my article on Infrastructure as Code here.
Production Deployment
After the model is trained and reaches certain accuracy, it gets deployed to production, where it starts making predictions against live data.
Application Code
Once the model is trained, it gets used by the application code (web service or an application) that consumes it to make predictions against live data. Continuous Integration for Application code goes through various steps to ensure the quality of code and packages the model into the artifact generated at the end of CI. (Note: You can also pull the model during runtime in production, but you lose the “Build Once, Run Anywhere” aspect with it.)
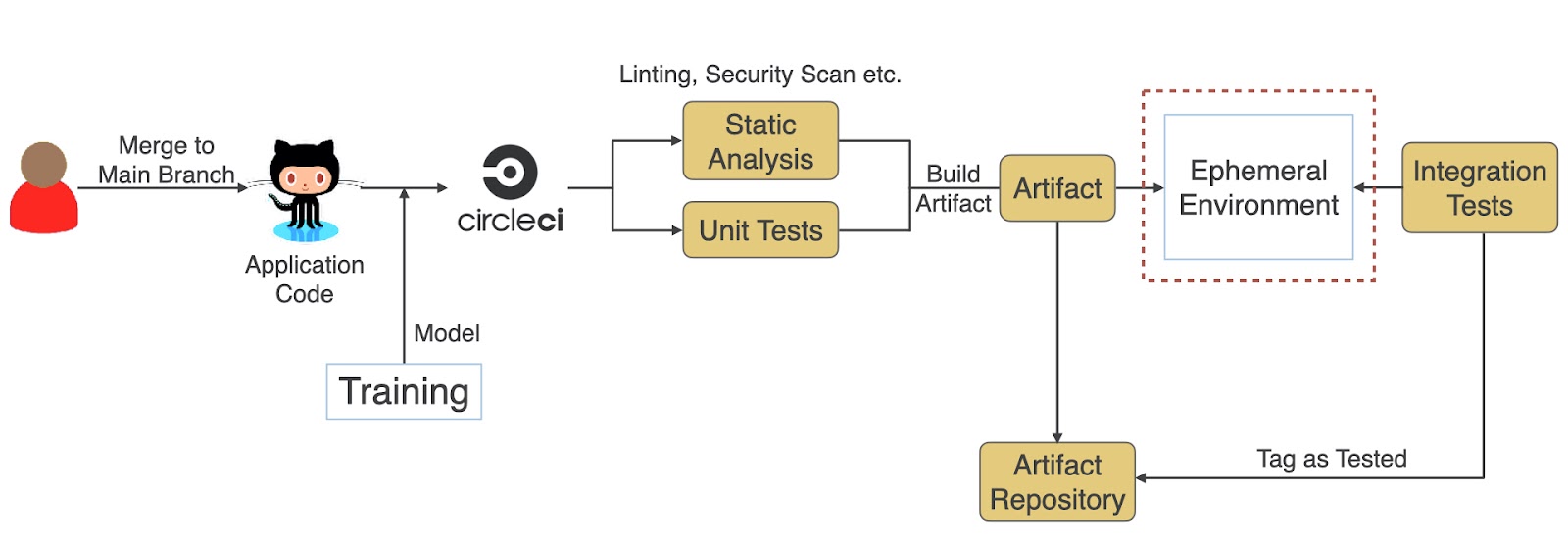
Challenges during production deployment that you can read about more here:
Challenge: Offline/Online Prediction
Solution: Providing support for offline(batch) and online(real-time) prediction depending on the needs is essential. When you are building a system for Production deployment, you should think about this aspect.
Challenge: Model Degradation
Solution: Adding smoke tests after every deployment and appropriate monitoring & alerting for model accuracy changes due to data drift or other reasons, and a good incident management process helps avoid and recover from accuracy levels going lower than accepted.
Bringing it all together
See the below diagram that brings all the stages/steps we have discussed so far for the end to end processing.
People
I will be writing a detailed article on this later, but people are essential for continuous delivery to be effective. Removing any silos between your ML Researchers, ML Engineers, Application Developers, Data Engineers, and DevOps/SRE folks and facilitating collaboration helps. Implementing the suggestions mentioned in this article will enable collaboration between various teams/individuals.
Conclusion
Thanks for reading the article, and I hope that you find it useful. If you have any questions, let me know in the comments below or reach out to me on twitter.